PyMC3 primer
Contents
#On Colab try:
#copy from https://github.com/cfteach/brds/blob/main/other/requirements_lec4_colab.txt
#%%writefile requirements.txt
#pip install -r requirements.txt
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import numpy as np
import pandas as pd
import seaborn as sns
import pymc3 as pm
import arviz as az
import requests
az.style.use('arviz-darkgrid')
%config InlineBackend.figure_format = 'retina'
az.style.use("arviz-darkgrid")
print(f"Running on PyMC3 v{pm.__version__}")
print(f"Running on ArviZ v{az.__version__}")
Running on PyMC3 v3.11.5
Running on ArviZ v0.12.1
PyMC3 primer#
# Let's create our dataset for the flipping coin problem
np.random.seed(123)
trials = 20
theta_real = 0.35 # unknown value in a real experiment (pretend to know it)
data = stats.bernoulli.rvs(p=theta_real, size=trials)
print(data, type(data)) #this is what you observe
data2 = [1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0]
data2 = np.array(data2)
print(data2, type(data2))
[1 0 0 0 1 0 1 1 0 0 0 1 0 0 0 1 0 0 0 0] <class 'numpy.ndarray'>
[1 0 0 0 1 0 1 1 0 0 0 1 0 0 0 1 0 0 0 0] <class 'numpy.ndarray'>
# Let's create our model in PyMC3
# the following creates a sort of container of our model
with pm.Model() as model: #everything inside the with-block will add to our_first_model
# prior
θ = pm.Beta('θ', alpha=1., beta=1.)
# likelihood
y = pm.Bernoulli('y', p=θ, observed=data) #using observed data tells PyMC this is the likelihood
#"The Inference Button"
idata = pm.sample(1000, random_seed=123, return_inferencedata=True) #https://docs.pymc.io/en/v3/api/inference.html
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [θ]
/Users/cfanelli/Desktop/teaching/BRDS/jupynb_env_new/lib/python3.9/site-packages/scipy/stats/_continuous_distns.py:624: RuntimeWarning: overflow encountered in _beta_ppf
return _boost._beta_ppf(q, a, b)
/Users/cfanelli/Desktop/teaching/BRDS/jupynb_env_new/lib/python3.9/site-packages/scipy/stats/_continuous_distns.py:624: RuntimeWarning: overflow encountered in _beta_ppf
return _boost._beta_ppf(q, a, b)
/Users/cfanelli/Desktop/teaching/BRDS/jupynb_env_new/lib/python3.9/site-packages/scipy/stats/_continuous_distns.py:624: RuntimeWarning: overflow encountered in _beta_ppf
return _boost._beta_ppf(q, a, b)
/Users/cfanelli/Desktop/teaching/BRDS/jupynb_env_new/lib/python3.9/site-packages/scipy/stats/_continuous_distns.py:624: RuntimeWarning: overflow encountered in _beta_ppf
return _boost._beta_ppf(q, a, b)
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 7 seconds.
With PyMC3 version >=3.9 the return_inferencedata=True kwarg makes the sample function return an arviz.InferenceData object instead of a MultiTrace. InferenceData has many advantages, compared to a MultiTrace: For example it can be saved/loaded from a file, and can also carry additional (meta)data such as date/version, or posterior predictive distributions. See here
(i) θ is used first as a Python variable then as the first argument of the Beta function; using the same name is a good practice to avoid confusion. The θ variable is a random variable; it is not a number but an object representing a probability distribution from which we can compute random numbers and probability densiities.
θ ~ Beta (α, β)y ~ Bern (p=θ)
(ii) Notice that using the observed data says to PyMC we are working with a Likelihood (in the example above is Bernoulli). The values of the data can be passed either as a Python list, a tuple, a numpy array or a pandas DataFrame.
(iii) The last line, with trace, is known as the "Inference Button". We are asking for 1000 samples from the posterior and will store them in the trace object. pyMC3 is doing a lot of things under the hood:
(a) Auto-assigning NUTS sampler... (NUTS is an inference engine for continuous variables)
(b) Initializing NUTS using jitter+adapt_diag... (method for initiliazing the sampler)
(c) Multiprocess sampling (4 chains in 4 jobs) (PyMC3 will run 4 chains in parallel; we will get 4 independnent samples from the posterior at the price of one; this is done taking into account the number of processors in your machine by default; otherwise, you can specify in the sample the argument 'chains')
(d) NUTS: [θ] (It tells us which variables are being sampled by which sampler. This is useful when things are more complicated than the problem we are dealing which has only θ)
Suppose we asked 1000 samples. The autotuning of NUTS takes 1000 iterations. If you have n chains, each will be 2000 (=500+1000). Therefore the total number of iterations is going to be: 2000*n
#print(idata)
print(np.shape(idata), type(idata))
print(idata['posterior']['θ'][3])
post_chain = idata['posterior']['θ'][3]
print(type(post_chain))
(4,) <class 'arviz.data.inference_data.InferenceData'>
<xarray.DataArray 'θ' (draw: 1000)>
array([0.25413149, 0.26956788, 0.26554305, 0.38890311, 0.33169636,
0.33169636, 0.33169636, 0.33169636, 0.45191069, 0.3126736 ,
0.3126736 , 0.19575665, 0.21405395, 0.45964194, 0.36348839,
0.34477404, 0.34477404, 0.1410477 , 0.12752922, 0.22593796,
0.43605942, 0.35175872, 0.36365463, 0.36365463, 0.35833546,
0.40105357, 0.30622827, 0.472057 , 0.472057 , 0.41429502,
0.4015957 , 0.47527784, 0.47527784, 0.35200729, 0.24111654,
0.24111654, 0.21239008, 0.2903128 , 0.2903128 , 0.29730441,
0.2610168 , 0.26732052, 0.31411239, 0.41194548, 0.36112494,
0.35961239, 0.15127028, 0.44463579, 0.44463579, 0.3881053 ,
0.26885622, 0.15308177, 0.37777333, 0.27771344, 0.29246245,
0.29246245, 0.46962063, 0.2930268 , 0.2287471 , 0.2287471 ,
0.28588129, 0.27787922, 0.27787922, 0.27787922, 0.27978702,
0.22886973, 0.27319566, 0.30890351, 0.2627965 , 0.29012315,
0.20241934, 0.23469934, 0.3590283 , 0.3590283 , 0.37779003,
0.31210844, 0.42500347, 0.36705026, 0.30339335, 0.31086282,
0.28614225, 0.28614225, 0.36577017, 0.36441152, 0.36441152,
0.59188056, 0.30936308, 0.22075668, 0.27679366, 0.37230168,
0.39022568, 0.39022568, 0.40572078, 0.20977073, 0.20977073,
0.20977073, 0.28984055, 0.25004915, 0.22810009, 0.24027512,
...
0.27288143, 0.27288143, 0.2869385 , 0.26761004, 0.38377393,
0.46319306, 0.46319306, 0.19774207, 0.47697691, 0.41316722,
0.15580426, 0.07980051, 0.1868928 , 0.33119767, 0.33119767,
0.17249866, 0.51187676, 0.34526685, 0.34526685, 0.23548269,
0.21570973, 0.34809797, 0.35302006, 0.36154391, 0.31843739,
0.36400832, 0.36400832, 0.39649546, 0.39649546, 0.28355596,
0.27929209, 0.19074473, 0.21242491, 0.31324342, 0.35943646,
0.41131245, 0.24918669, 0.21337022, 0.27357124, 0.24449123,
0.23519251, 0.29536006, 0.29536006, 0.27146541, 0.13885775,
0.16202496, 0.22000499, 0.24123212, 0.19180491, 0.19546866,
0.11967518, 0.39786583, 0.25225099, 0.31466868, 0.36517219,
0.33566636, 0.38175771, 0.38175771, 0.1963503 , 0.21361871,
0.35015722, 0.38865789, 0.38865789, 0.14806516, 0.48642805,
0.48642805, 0.33596087, 0.33596087, 0.12913337, 0.25008185,
0.21990255, 0.1158873 , 0.45695984, 0.34971066, 0.45305183,
0.45305183, 0.36610944, 0.38033667, 0.38033667, 0.16821574,
0.28622382, 0.28622382, 0.28622382, 0.35707782, 0.35707782,
0.33556605, 0.34317844, 0.37377388, 0.41350492, 0.38986633,
0.37526948, 0.35533573, 0.46284388, 0.36807115, 0.37985616,
0.37985616, 0.19826559, 0.24261578, 0.39252004, 0.11240422])
Coordinates:
chain int64 3
* draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 992 993 994 995 996 997 998 999
<class 'xarray.core.dataarray.DataArray'>
Summarizing the posterior#
az.plot_trace(idata, combined = False, compact=False)
plt.savefig('./output/B11197_02_01.png')

Depending on the number of chains (N), you have N curves.
The plots on the left are obtained from Kernel Density Estimation (KDE) of the corresponding histograms, while the plots on the right are the sampled values from each chain.
You should compare these curves with those obtained analytically in the previous lecture.
#it returns a Pandas dataframe
az.summary(idata)
# Got error No model on context stack. if return_inferencedata=False
# However, if return_inferencedata=False trace['θ'] not found...
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| θ | 0.32 | 0.096 | 0.138 | 0.497 | 0.002 | 0.002 | 1706.0 | 2561.0 | 1.0 |
That’s the mean from all the chains… HDI are simple to understand at this point. The other metrics will be explained in the following lectures, but for now know that they are used to interpret the results of a Bayesian inference.
HPD: High Posterior Density; HDI: is the highest density interval. Another way of summarizing a distribution, which we will use often, abbreviated HDI. The HDI indicates which points of a distribution are most credible, and which cover most of the distribution.
They are often used as synonyms in the legends of the plots.
If you want to learn more:
ess: effective-sample size
ess_bulk: useful measure for sampling efficiency in the bulk of the distribution. The rule of thumb for ess_bulk is for this value to be greater than 100 per chain on average. Since we ran N chains, we need ess_bulk to be greater than N*100 for each parameter.
ess_tail: compute a tail effective sample size estimate for a single variable. The rule of thumb for this value is also to be greater than 100 per chain on average.
r_hat: diagnostic tests for lack of convergence by comparing the variance between multiple chains to the variance within each chain. converges to unity when each of the traces is a sample from the target posterior. Values greater than one indicate that one or more chains have not yet converged.
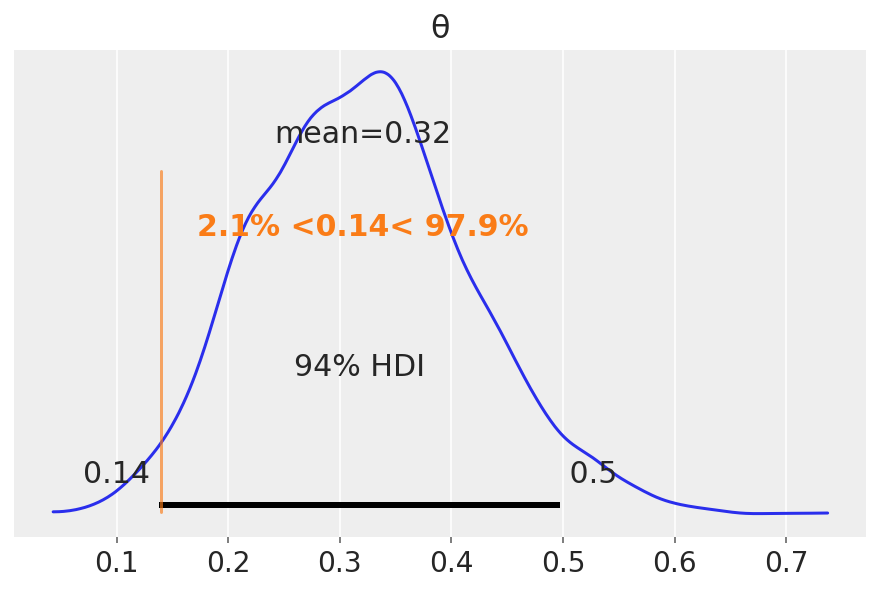
Posterior-based decisions (Is the coin fair?)#
Strictly speaking, a fair coin θ=0.5. But the probability of observing exactly 0.5 is practcally 0. We can relax this definition of fairness to a Region of Practical Equivalence (ROPE), say [0.45,0.55] (it depends on your expectations and prior knowledge and it is always context-dependent).
There are three scenarios:
the ROPE does not overlap with the HDI; the coin is not fair
the ROPE contains the entire HDI; the coin is fair
the ROPE partially overlaps with HDI; we cannot make any conclusions
az.plot_posterior(idata, hdi_prob=0.99999)
plt.savefig('./output/B11197_02_02.png', dpi=300)
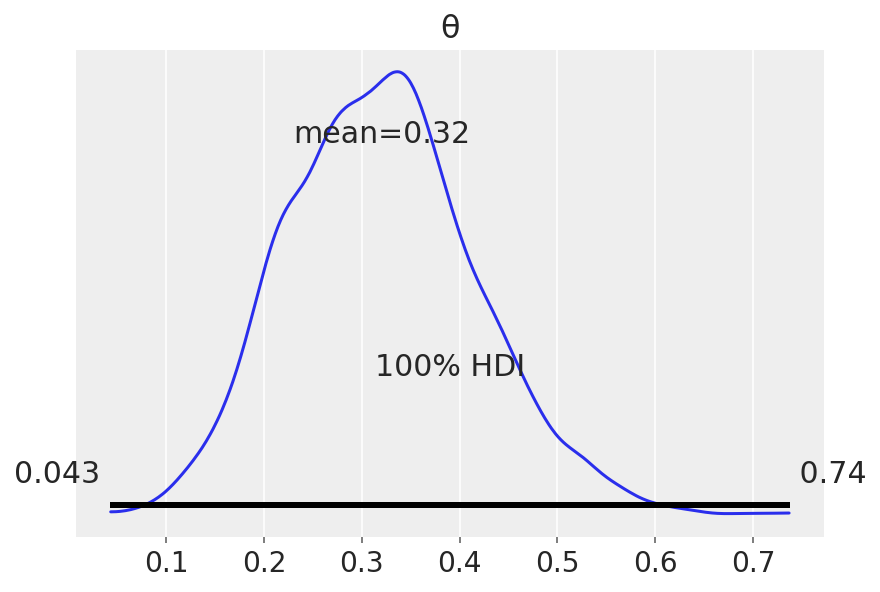
az.plot_posterior(idata, rope=[0.14, .5])
plt.savefig('./output/B11197_02_03.png', dpi=300)
Unlike a frequentist approach, Bayesian inference is not based on statistical significance, where effects are tested against “zero”. Indeed, the Bayesian framework offers a probabilistic view of the parameters, allowing assessment of the uncertainty related to them. Thus, rather than concluding that an effect is present when it simply differs from zero, we would conclude that the probability of being outside a specific range that can be considered as “practically no effect” (i.e., a negligible magnitude) is sufficient. This range is called the region of practical equivalence (ROPE).
Therefore, the idea underlining ROPE is to let the user define an area around the null value enclosing values that are equivalent to the null value for practical purposes
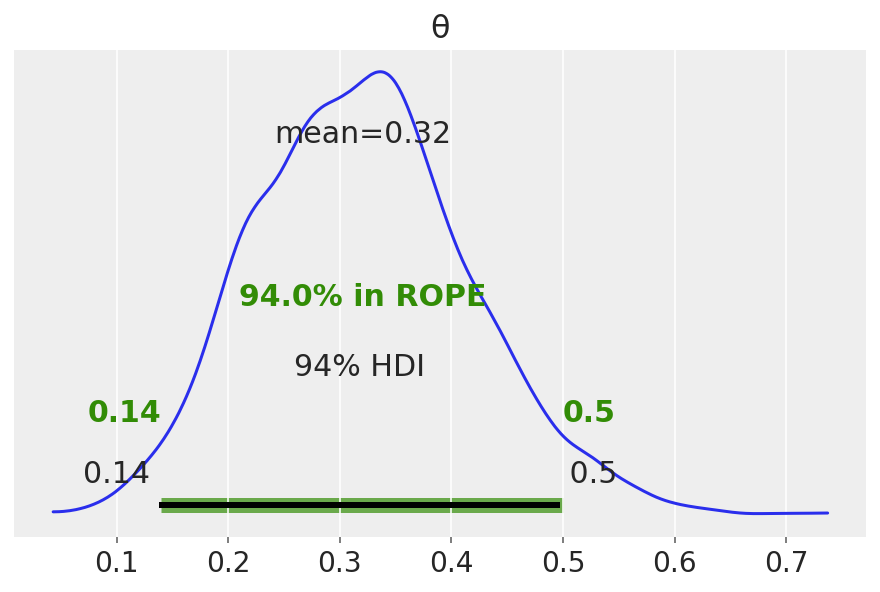
az.plot_posterior(idata, ref_val=0.14)
plt.savefig('./output/B11197_02_04.png', dpi=300)
Loss functions: how close to the truth are we?#
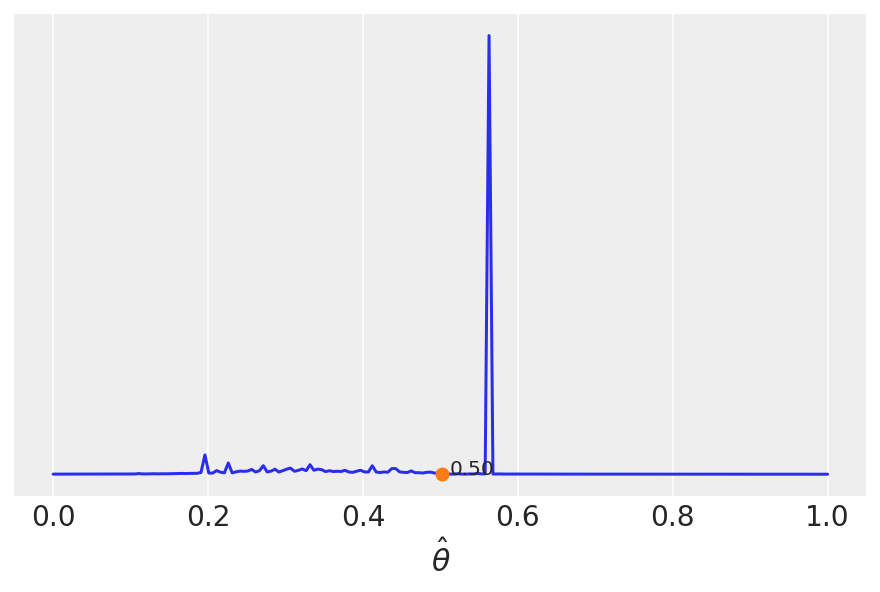
We can find the value of \(\hat{\theta}\) that minimizes the loss function(s) below.
grid = np.linspace(0, 1, 200) #Le'ts explore a grid of 200 points
nchain = 0
θ_pos = idata['posterior']['θ'][nchain] #for the nth first chain
print(θ_pos)
#------ here add also the "average" chain ------#
lossf_a = [np.mean(abs(i - θ_pos)) for i in grid] #Absolute Loss
lossf_b = [np.mean((i - θ_pos)**2) for i in grid] #Quadratic Loss
for lossf, c in zip([lossf_a, lossf_b], ['C0', 'C1']):
mini = np.argmin(lossf)
plt.plot(grid, lossf, c)
plt.plot(grid[mini], lossf[mini], 'o', color=c)
plt.annotate('{:.2f}'.format(grid[mini]),
(grid[mini], lossf[mini] + 0.03), color=c)
plt.yticks([])
plt.xlabel(r'$\hat \theta$')
plt.savefig('./output/B11197_02_05.png', dpi=300)
check_mean = np.mean(θ_pos)
check_median = np.median(θ_pos)
print('mean: {:3.2f}, median: {:3.2f}'.format(check_mean,check_median))
<xarray.DataArray 'θ' (draw: 1000)>
array([0.35986819, 0.23793445, 0.27472342, 0.34777275, 0.46235901,
0.1630317 , 0.31669555, 0.37883126, 0.33795245, 0.48356288,
0.38120963, 0.26406215, 0.38582085, 0.57699365, 0.47992564,
0.15988675, 0.5516593 , 0.16191774, 0.25610834, 0.52809551,
0.25547977, 0.17300396, 0.21062766, 0.18926698, 0.22679219,
0.41337775, 0.44661721, 0.45597114, 0.32436655, 0.34509972,
0.39478497, 0.28593878, 0.26289785, 0.28533806, 0.21800791,
0.24311865, 0.32646302, 0.30632996, 0.34421134, 0.35700624,
0.30651727, 0.33843605, 0.32990145, 0.32990145, 0.29930425,
0.17317636, 0.16353757, 0.56281394, 0.46046256, 0.46046256,
0.208586 , 0.1974908 , 0.43106712, 0.45270041, 0.24810727,
0.21383876, 0.48750785, 0.38125267, 0.46186692, 0.39161742,
0.35978344, 0.31574192, 0.22043384, 0.25630947, 0.23343554,
0.27436605, 0.1564859 , 0.17062229, 0.1572067 , 0.279454 ,
0.26510465, 0.33241055, 0.33241055, 0.36933485, 0.18314664,
0.18314664, 0.17684266, 0.20048061, 0.2525933 , 0.2525933 ,
0.26713454, 0.32935323, 0.32935323, 0.22612661, 0.15380947,
0.33573488, 0.33202538, 0.36417702, 0.30564146, 0.24742538,
0.27871137, 0.18711206, 0.19618314, 0.24487698, 0.29484858,
0.33521221, 0.3500276 , 0.45503577, 0.30303425, 0.31447388,
...
0.28730952, 0.37416473, 0.39870614, 0.22715366, 0.30540043,
0.24109083, 0.24003391, 0.24003391, 0.31393328, 0.2521011 ,
0.32547285, 0.32547285, 0.45371678, 0.22707331, 0.37744095,
0.28733045, 0.17621198, 0.26957846, 0.39099302, 0.41994913,
0.21903393, 0.27986717, 0.28150703, 0.31819665, 0.3196977 ,
0.45516111, 0.21946515, 0.23362021, 0.43188303, 0.36724457,
0.29265562, 0.28431276, 0.13433931, 0.19889503, 0.19889503,
0.20159266, 0.40134858, 0.45478616, 0.29723575, 0.29364812,
0.37794922, 0.44915937, 0.44915937, 0.34070321, 0.28294589,
0.29441698, 0.29441698, 0.41730201, 0.36624934, 0.38526048,
0.41264646, 0.34745866, 0.3365048 , 0.3365048 , 0.33381656,
0.48249416, 0.39629296, 0.24249243, 0.19256846, 0.21118406,
0.21086844, 0.21347245, 0.21347245, 0.20453277, 0.13203623,
0.29414727, 0.29352201, 0.43644133, 0.33169766, 0.42028181,
0.15197309, 0.28529336, 0.24720682, 0.25213633, 0.25213633,
0.24154764, 0.27865203, 0.27831912, 0.20255332, 0.25330583,
0.11812659, 0.51656964, 0.4396739 , 0.35464337, 0.34563145,
0.24817439, 0.3242482 , 0.1850232 , 0.18472814, 0.26843548,
0.36299204, 0.40674057, 0.43179094, 0.51431637, 0.51431637,
0.30216127, 0.40225216, 0.33149639, 0.33149639, 0.30193819])
Coordinates:
chain int64 0
* draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 992 993 994 995 996 997 998 999
mean: 0.32, median: 0.32
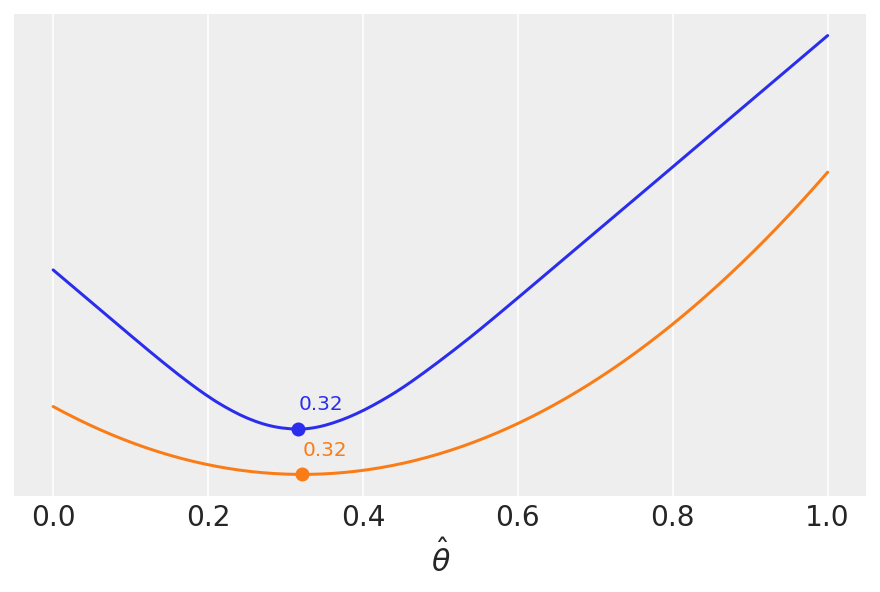
We saw this heuristically (calculating the mean and the median), but the key message is that different loss functions are related to different point-estimates. Compare to the plot above.
Cost functions could be asymmetric.
A dummy example is the following.
lossf = []
for i in grid:
if i < 0.5:
f = np.mean(np.pi * θ_pos / np.abs(i - θ_pos))
else:
f = np.mean(1 / (i - θ_pos))
lossf.append(f)
mini = np.argmin(lossf)
plt.plot(grid, lossf)
plt.plot(grid[mini], lossf[mini], 'o')
plt.annotate('{:.2f}'.format(grid[mini]),
(grid[mini] + 0.01, lossf[mini] + 0.1))
plt.yticks([])
plt.xlabel(r'$\hat \theta$')
plt.savefig('./output/B11197_02_06.png', dpi=300)