26. Conditional Generative Adverserial Network#
from IPython.display import Image
%matplotlib inline
26.1. Using Conditional GAN for MNIST dataset#
The primary difference between a DCGAN (Deep Convolutional GAN) and a Conditional DCGAN (cDCGAN) lies in the use of conditioning information. Let’s break down these distinctions clearly:
26.1.1. 1. Core Idea#
DCGAN: A DCGAN generates images without any control over the content. It generates realistic-looking samples based solely on random noise input, learning to mimic the distribution of a dataset without any particular focus on classes or categories.
Conditional DCGAN (cDCGAN): A cDCGAN generates images conditioned on specific labels or auxiliary information. For example, on the MNIST dataset, a cDCGAN can be trained to generate images of specific digits (0-9) by providing label information (the digit) along with the noise vector.
Some resources:
26.1.2. 2. Generator Architecture#
DCGAN Generator: Takes a random noise vector as input and transforms it through a series of convolutional layers to generate an image. It does not take any class information, so there’s no control over what type of image (e.g., which digit) it generates.
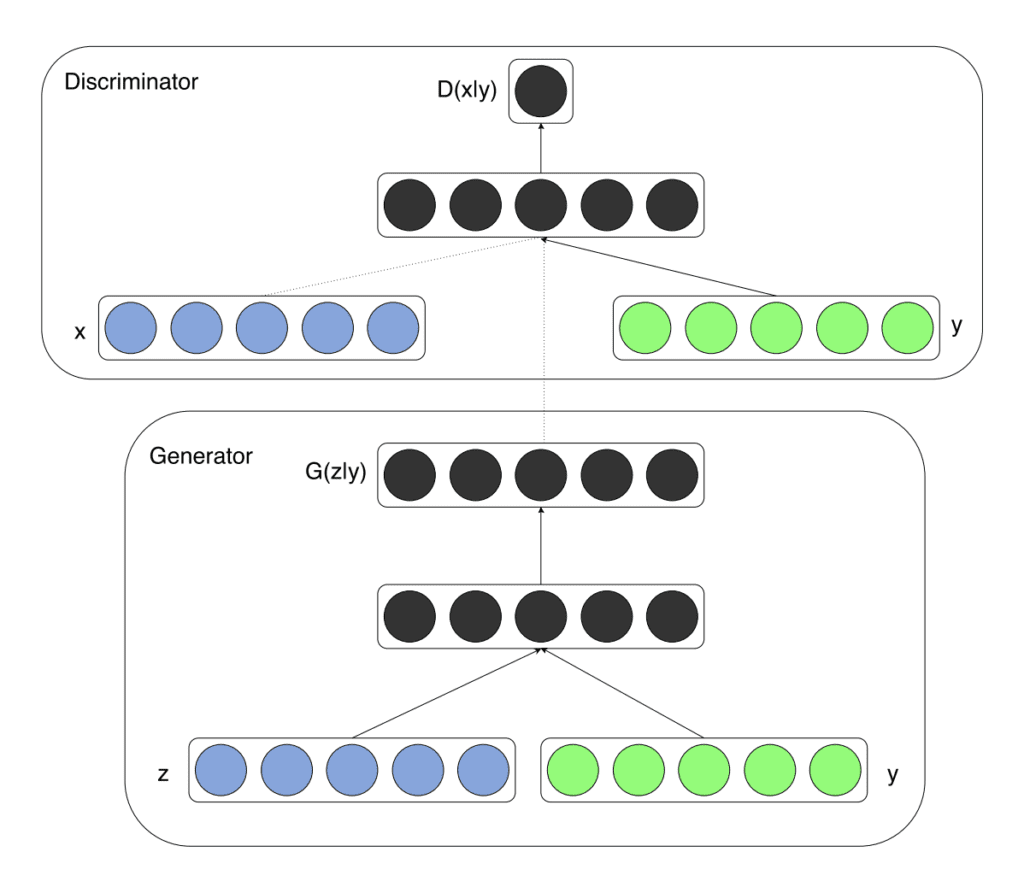
cDCGAN Generator: In addition to the noise vector, the generator receives a label embedding that represents the conditioning information (e.g., digit label 0-9). The noise and label embedding are concatenated and fed together through the generator’s convolutional layers. This allows the generator to create images specific to the input label.
26.1.3. 3. Discriminator Architecture#
DCGAN Discriminator: The DCGAN discriminator only receives an image (either real or generated) as input and learns to classify it as real or fake. It does not consider any additional information about the image’s content.
cDCGAN Discriminator: The cDCGAN discriminator receives both an image and its corresponding label as input. The label is embedded and concatenated with the image data. This setup helps the discriminator to determine if the generated image is not only realistic but also matches the provided label, making it a more nuanced judge in the adversarial process.
26.1.3.1. Conditional Probability Distributions#
Real Data Distribution: \( p_{\text{data}}(x | y) \)
Generator’s Distribution: \( p_G(x | y) \)
The \(x\) and \(y\) could be thought of as channels in the image, and \(y\) could be thought of as the class label embedded as another channel. (This is one of the way of implementing cGANs.)
26.1.3.2. Objective Function#
The value function \( V(G, D) \) for a cGAN is defined as:
26.1.4. 4. Loss Function#
In cGANs, both the Generator and the Discriminator are conditioned on \(y\). The loss functions are modified to incorporate this conditioning, allowing the model to learn the joint distribution of data and conditioning variables.
26.1.4.1. Discriminator Loss#
The Discriminator aims to maximize the probability of correctly classifying real and generated data. The loss function for the Discriminator \(D\) is:
26.1.4.2. Generator Loss#
The Generator tries to minimize the probability that the Discriminator correctly identifies its outputs as fake. The loss function for the Generator \( G \) is:
Alternatively, to improve gradient flow, the Generator’s loss can be formulated using the least squares loss or other variations.
26.2. 5. Combining the Loss Functions#
The training of a cGAN involves optimizing both \( G \) and \( D \) simultaneously. However, since \( G \) and \( D \) have opposing objectives, their loss functions are optimized alternately:
Update Discriminator \( D \): Maximize \( \mathcal{L}_D \)
Update Generator \( G \): Minimize \( \mathcal{L}_G \)
The losses are combined in the sense that the optimization of one depends on the performance of the other. However, they are not summed together; instead, they are used to update their respective networks during training iterations.
26.2.1. 6. Training Objective#
DCGAN: Trains the generator to produce images that look as real as possible, while the discriminator is trained to differentiate between real and fake images.
cDCGAN: Trains the generator not only to create realistic images but also to create images that match the specified class label. The discriminator is trained to recognize if the image aligns with the label, adding a class-matching constraint on top of the real-vs-fake classification.
26.2.1.1. Training Process#
Discriminator Update:
Goal: Maximize \( V(G, D) \) with respect to \( D \)
Loss Function:
Optimization: Update \( D \) to minimize \( \mathcal{L}_D \)
Generator Update:
Goal: Minimize \( V(G, D) \) with respect to \( G \)
Loss Function:
Optimization: Update \( G \) to minimize \( \mathcal{L}_G \)
26.2.2. 7. Applications and Benefits#
DCGAN: Useful for general image generation tasks where specific control over the image content isn’t required. It’s often used for tasks like unsupervised feature learning and image generation in unstructured datasets.
cDCGAN: Useful when specific control over the image content is needed, such as generating images of specific categories or classes. Conditioning information provides control, making it ideal for applications like digit generation in MNIST, where you may want to generate images of a specific digit (0-9), or face generation, where specific attributes can be targeted.
26.2.3. Summary Table#
Feature |
DCGAN |
Conditional DCGAN (cDCGAN) |
|---|---|---|
Input to Generator |
Noise vector |
Noise vector + label embedding |
Input to Discriminator |
Image |
Image + label embedding |
Output Control |
Random (no control over class/type) |
Controlled by label (e.g., generates specific digits) |
Generator’s Goal |
Generate realistic images |
Generate realistic images of a specific class |
Discriminator’s Goal |
Distinguish real vs. fake images |
Distinguish if the image is real and matches the label |
import torch
print(torch.__version__)
print("GPU Available:", torch.cuda.is_available())
if torch.cuda.is_available():
device = torch.device("cuda:0")
else:
device = "cpu"
2.6.0+cu124
GPU Available: True
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
26.3. Train the DCGAN model#
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
# Set device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load MNIST dataset
image_path = './'
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
mnist_dataset = torchvision.datasets.MNIST(root=image_path,
train=True,
transform=transform,
download=True)
batch_size = 128
mnist_dl = DataLoader(mnist_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
100%|██████████| 9.91M/9.91M [00:02<00:00, 4.62MB/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 134kB/s]
100%|██████████| 1.65M/1.65M [00:01<00:00, 1.27MB/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 7.47MB/s]
# Generator network with conditioning (for cDCGAN)
class ConditionalGenerator(nn.Module):
def __init__(self, z_dim, n_classes, n_filters):
super(ConditionalGenerator, self).__init__()
self.label_embedding = nn.Embedding(n_classes, z_dim)
# each class mapped into a z_dim, hence [B, z_dim, 1, 1]
self.initial = nn.ConvTranspose2d(z_dim, n_filters * 4, 4, 1, 0, bias=False) # (B, z_dim, 1, 1) -> (B, n_filters*4, 4, 4)
self.initial_bn = nn.BatchNorm2d(n_filters * 4)
self.initial_act = nn.LeakyReLU(0.2, inplace=True)
# Project z again to match shape for residual injection
self.noise_injection = nn.Sequential(
nn.Conv2d(z_dim, n_filters * 4, kernel_size=1),
nn.Tanh()
) # (B, z_dim, 1, 1) -> (B, n_filters*4, 1, 1)
# input is (B, n_filters*4, 4, 4)
self.upsample = nn.Sequential(
# torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding)
# o = (n-1)*s - 2p + k + o_p
nn.ConvTranspose2d(n_filters * 4, n_filters * 2, 3, 2, 1, bias=False),
# o = 3*2 - 2 + 3 = 7
# (B,n_filters*2,7,7)
nn.BatchNorm2d(n_filters * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose2d(n_filters * 2, n_filters, 4, 2, 1, bias=False),
# o = 6*2 - 2 + 4 = 14
# (B,n_filters,14,14)
nn.BatchNorm2d(n_filters),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose2d(n_filters, 1, 4, 2, 1, bias=False),
# o = 13*2 - 2 + 4 = 28
# (B,1,28,28)
nn.Tanh()
)
def forward(self, noise, labels):
#label_embedding = self.label_embedding(labels).unsqueeze(2).unsqueeze(3) # (B, z_dim, 1, 1)
#input = torch.cat([noise, label_embedding], dim=1) # (B, 2*z_dim, 1, 1)
label_embedding = self.label_embedding(labels).unsqueeze(2).unsqueeze(3)
input = noise * label_embedding # Element-wise multiplication
# noise: [B, z_dim, 1, 1]
# label_embedding: [B, z_dim, 1, 1]
# Initial upsampling
out = self.initial(input) # (B, z_dim, 1, 1) -> (B, n_filters*4, 4, 4)
out = self.initial_bn(out)
out = self.initial_act(out)
# Inject noise directly into feature map (residual connection)
noise_injected = self.noise_injection(noise) # (B, z_dim, 1, 1) -> (B, n_filters*4, 1, 1)
out = out + noise_injected # Broadcasted addition
return self.upsample(out)
# Discriminator network with conditioning (for cDCGAN)
class ConditionalDiscriminator(nn.Module):
def __init__(self, n_classes, n_filters, img_size = torch.Size([1, 28, 28])):
super(ConditionalDiscriminator, self).__init__()
# Embedding layer for labels:
# This layer takes the class label (e.g., digits 0-9 in MNIST) and produces a vector
# representation, which will be reshaped and concatenated with the input image.
# In a standard DCGAN, there is no need for this label embedding because the discriminator
# only receives the image without any additional class information.
self.img_size = img_size
self.label_embedding = nn.Embedding(n_classes, img_size.numel()) # numel returns the total number of elements in a tensor, e.g., 1 × 28 × 28 = 784
# Main Discriminator Network:
# Similar to DCGAN, we use a series of convolutional layers to process the input.
# However, the input now has an extra channel to accommodate the concatenated label.
self.model = nn.Sequential(
# Input layer: (2 channels, 28x28) where the 2 channels are the image and label embedding
# Conv2d: in_channels=2, out_channels=n_filters, kernel=4, stride=2, padding=1
nn.Conv2d(2, n_filters, 4, 2, 1, bias=False),
# Output: (batch_size, n_filters, 14, 14)
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
# Additional convolutional layers to downsample and extract features
# Conv2d: in_channels=n_filters, out_channels=n_filters*2, kernel=4, stride=2, padding=1
nn.Conv2d(n_filters, n_filters * 2, 4, 2, 1, bias=False),
# Output: (batch_size, n_filters*2, 7, 7)
nn.BatchNorm2d(n_filters * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
# Conv2d: in_channels=n_filters*2, out_channels=n_filters*4, kernel=3, stride=2, padding=1
nn.Conv2d(n_filters * 2, n_filters * 4, 3, 2, 1, bias=False),
# Output: (batch_size, n_filters*4, 4, 4)
nn.BatchNorm2d(n_filters * 4),
nn.LeakyReLU(0.2, inplace=True),
# Final layer outputs a single value indicating real/fake classification
# Conv2d: in_channels=n_filters*4, out_channels=1, kernel=4, stride=1, padding=0
nn.Conv2d(n_filters * 4, 1, 4, 1, 0, bias=False),
# Output: (batch_size, 1, 1, 1)
nn.Sigmoid()
)
def forward(self, img, labels):
# Conditional Input Preparation:
# For each input label, we use the embedding layer to convert it into a 28x28 feature map
# that matches the spatial dimensions of the input image. This embedding acts as a "template"
# guiding the discriminator in recognizing if the image matches the class label.
label_embedding = self.label_embedding(labels).view(labels.size(0), self.img_size[0], self.img_size[1], self.img_size[2])
# Concatenate image and label embedding along the channel dimension:
# The discriminator now receives both the image and label information as input.
# In a standard DCGAN, only the image is passed in, so the discriminator only learns to
# differentiate real vs. fake without considering specific classes.
input = torch.cat([img, label_embedding], dim=1)
# Forward pass through the discriminator model
return self.model(input).view(-1, 1)
# Initialize models
z_size = 128
n_classes = 10
n_filters = 64
image_size = (28, 28)
gen_model = ConditionalGenerator(z_size, n_classes, n_filters).to(device)
print(gen_model)
disc_model = ConditionalDiscriminator(n_classes, n_filters).to(device)
print(disc_model)
# Loss and optimizers
loss_fn = nn.BCELoss()
g_optimizer = torch.optim.Adam(gen_model.parameters(), lr=0.0003)
d_optimizer = torch.optim.Adam(disc_model.parameters(), lr=0.0002)
ConditionalGenerator(
(label_embedding): Embedding(10, 128)
(initial): ConvTranspose2d(128, 256, kernel_size=(4, 4), stride=(1, 1), bias=False)
(initial_bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(initial_act): LeakyReLU(negative_slope=0.2, inplace=True)
(noise_injection): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Tanh()
)
(upsample): Sequential(
(0): ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2, inplace=True)
(3): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.2, inplace=True)
(6): ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): Tanh()
)
)
ConditionalDiscriminator(
(label_embedding): Embedding(10, 784)
(model): Sequential(
(0): Conv2d(2, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Dropout2d(p=0.3, inplace=False)
(3): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.2, inplace=True)
(6): Dropout2d(p=0.3, inplace=False)
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(8): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): LeakyReLU(negative_slope=0.2, inplace=True)
(10): Conv2d(256, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(11): Sigmoid()
)
)
# Helper functions
def create_noise(batch_size, z_dim, mode='uniform'):
if mode == 'uniform':
return torch.rand(batch_size, z_dim, 1, 1, device=device) * 2 - 1
elif mode == 'normal':
return torch.randn(batch_size, z_dim, 1, 1, device=device)
## Train the discriminator (for cDCGAN)
def d_train(x, labels):
# Zero the gradients for the discriminator
disc_model.zero_grad()
# Train discriminator with a real batch
# ======================================
# In a Conditional GAN, we not only provide real images (x) but also the corresponding labels.
# These labels allow the discriminator to understand the "context" of each real image.
batch_size = x.size(0)
x = x.to(device) # Move images to the device (e.g., GPU)
labels = labels.to(device) # Move labels to the device
# Real labels for real images
d_labels_real = torch.ones(batch_size, 1, device=device)
# Get discriminator's prediction on real images with correct labels
d_proba_real = disc_model(x, labels) # In a DCGAN, only x (images) would be used here
d_loss_real = loss_fn(d_proba_real, d_labels_real) # Compute loss for real images
# Train discriminator on a fake batch
# ===================================
# To generate a fake batch, we use random noise and random labels. The generator uses
# both to create images that correspond to specific labels.
input_z = create_noise(batch_size, z_size, mode_z).to(device)
fake_labels = torch.randint(0, n_classes, (batch_size,), device=device) # Random labels
g_output = gen_model(input_z, fake_labels) # Generate images conditioned on these labels
# Get discriminator's prediction on fake images with fake labels
d_proba_fake = disc_model(g_output, fake_labels) # In a DCGAN, labels aren't used here
d_labels_fake = torch.zeros(batch_size, 1, device=device)
# Compute loss for fake images
d_loss_fake = loss_fn(d_proba_fake, d_labels_fake)
# Gradient backpropagation & update ONLY discriminator's parameters
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
d_optimizer.step()
# Return discriminator loss and probabilities for analysis
return d_loss.data.item(), d_proba_real.detach(), d_proba_fake.detach()
## Train the generator (for cDCGAN)
def g_train(x, labels):
# Zero the gradients for the generator
gen_model.zero_grad()
# Get batch size from the input images
batch_size = x.size(0)
# Generate a batch of noise vectors and random labels for the fake images
input_z = create_noise(batch_size, z_size, mode_z).to(device)
g_labels_real = torch.ones((batch_size, 1), device=device) # Real labels for generator loss
# Generate random labels for conditioning the fake images
fake_labels = torch.randint(0, n_classes, (batch_size,), device=device) # Random labels
# Generate fake images conditioned on random labels
g_output = gen_model(input_z, fake_labels) # In a DCGAN, labels are not used
# Get discriminator's prediction on the fake images and labels
d_proba_fake = disc_model(g_output, fake_labels) # In a DCGAN, labels are not included
g_loss = loss_fn(d_proba_fake, g_labels_real) # Goal: make discriminator believe fake images are real
# Gradient backpropagation & optimize ONLY generator's parameters
g_loss.backward()
g_optimizer.step()
# Return generator loss for analysis
return g_loss.data.item()
fixed_labels = torch.arange(n_classes).repeat(2*batch_size // n_classes)[:batch_size].to(device)
print (fixed_labels.shape)
print (fixed_labels)
torch.Size([128])
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3,
4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7,
8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1,
2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5,
6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7], device='cuda:0')
mode_z = 'uniform'
fixed_z = create_noise(batch_size, z_size, mode_z).to(device)
fixed_labels = torch.arange(n_classes).repeat(2*batch_size // n_classes)[:batch_size].to(device)
def create_samples(g_model, labels, input_z, batch_size):
g_output = g_model(input_z, labels)
images = torch.reshape(g_output, (batch_size, *image_size))
return (images+1)/2.0
epoch_samples = []
num_epochs = 50
torch.manual_seed(1)
for epoch in range(1, num_epochs+1):
gen_model.train()
d_losses, g_losses = [], []
for i, (x, labels) in enumerate(mnist_dl):
d_loss, d_proba_real, d_proba_fake = d_train(x, labels)
d_losses.append(d_loss)
g_losses.append(g_train(x, labels))
print(f'Epoch {epoch:03d} | Avg Losses >>'
f' G/D {torch.FloatTensor(g_losses).mean():.4f}'
f'/{torch.FloatTensor(d_losses).mean():.4f}')
gen_model.eval()
epoch_samples.append(
create_samples(gen_model, fixed_labels, fixed_z, batch_size).detach().cpu().numpy())
Epoch 001 | Avg Losses >> G/D 4.4991/0.2348
Epoch 002 | Avg Losses >> G/D 4.1311/0.2754
Epoch 003 | Avg Losses >> G/D 3.6849/0.3744
Epoch 004 | Avg Losses >> G/D 2.6861/0.6474
Epoch 005 | Avg Losses >> G/D 2.0610/0.8439
Epoch 006 | Avg Losses >> G/D 1.7810/0.8526
Epoch 007 | Avg Losses >> G/D 1.7568/0.8621
Epoch 008 | Avg Losses >> G/D 1.6006/0.9888
Epoch 009 | Avg Losses >> G/D 1.5149/0.9898
Epoch 010 | Avg Losses >> G/D 1.3822/1.0436
Epoch 011 | Avg Losses >> G/D 1.3257/1.1047
Epoch 012 | Avg Losses >> G/D 1.2473/1.1295
Epoch 013 | Avg Losses >> G/D 1.1824/1.1849
Epoch 014 | Avg Losses >> G/D 1.1394/1.1972
Epoch 015 | Avg Losses >> G/D 1.1285/1.2039
Epoch 016 | Avg Losses >> G/D 1.1295/1.2027
Epoch 017 | Avg Losses >> G/D 1.1030/1.2003
Epoch 018 | Avg Losses >> G/D 1.0856/1.2085
Epoch 019 | Avg Losses >> G/D 1.0236/1.2119
Epoch 020 | Avg Losses >> G/D 1.0069/1.2375
Epoch 021 | Avg Losses >> G/D 1.0442/1.2269
Epoch 022 | Avg Losses >> G/D 0.9935/1.2431
Epoch 023 | Avg Losses >> G/D 0.9744/1.2319
Epoch 024 | Avg Losses >> G/D 1.0105/1.2330
Epoch 025 | Avg Losses >> G/D 0.9907/1.2655
Epoch 026 | Avg Losses >> G/D 0.9535/1.2556
Epoch 027 | Avg Losses >> G/D 0.9626/1.2532
Epoch 028 | Avg Losses >> G/D 0.9820/1.2821
Epoch 029 | Avg Losses >> G/D 0.9307/1.2909
Epoch 030 | Avg Losses >> G/D 0.9442/1.2664
Epoch 031 | Avg Losses >> G/D 0.9464/1.2595
Epoch 032 | Avg Losses >> G/D 0.9540/1.2707
Epoch 033 | Avg Losses >> G/D 0.9512/1.2571
Epoch 034 | Avg Losses >> G/D 0.9342/1.2812
Epoch 035 | Avg Losses >> G/D 0.9587/1.2822
Epoch 036 | Avg Losses >> G/D 0.9697/1.2965
Epoch 037 | Avg Losses >> G/D 0.9213/1.2768
Epoch 038 | Avg Losses >> G/D 0.9461/1.2625
Epoch 039 | Avg Losses >> G/D 0.9786/1.2688
Epoch 040 | Avg Losses >> G/D 0.9154/1.2823
Epoch 041 | Avg Losses >> G/D 0.8929/1.2856
Epoch 042 | Avg Losses >> G/D 0.9075/1.2966
Epoch 043 | Avg Losses >> G/D 0.9428/1.2892
Epoch 044 | Avg Losses >> G/D 0.9379/1.2762
Epoch 045 | Avg Losses >> G/D 0.8922/1.3063
Epoch 046 | Avg Losses >> G/D 0.8880/1.2910
Epoch 047 | Avg Losses >> G/D 0.9105/1.2941
Epoch 048 | Avg Losses >> G/D 0.9189/1.3033
Epoch 049 | Avg Losses >> G/D 0.9122/1.2866
Epoch 050 | Avg Losses >> G/D 0.9036/1.2754
selected_epochs = [1, 2, 4, 8, 29]
fig = plt.figure(figsize=(20, 10))
for i,e in enumerate(selected_epochs):
for j in range(10):
ax = fig.add_subplot(6, 10, i*10+j+1)
ax.set_xticks([])
ax.set_yticks([])
if j == 0:
ax.text(
-0.06, 0.5, f'Epoch {e}',
rotation=90, size=18, color='red',
horizontalalignment='right',
verticalalignment='center',
transform=ax.transAxes)
image = epoch_samples[e-1][j]
ax.imshow(image, cmap='gray_r')
plt.show()

import matplotlib.pyplot as plt
from torchvision.utils import make_grid
fig, axs = plt.subplots(n_classes, 10, figsize=(12, 12))
for digit in range(n_classes):
z = create_noise(10, z_size, mode_z).to(device)
labels = torch.full((10,), digit, dtype=torch.long).to(device)
with torch.no_grad():
samples = create_samples(gen_model, labels, z, 10)
for i in range(10):
axs[digit, i].imshow(samples[i].squeeze().cpu().numpy(), cmap='gray_r')
axs[digit, i].axis('off')
if i == 0:
axs[digit, i].set_title(f"Label {digit}")
plt.suptitle("Rows = Same Label, Varying z")
plt.show()

# Generate a Digit by Label
def generate_digit_by_label(gen_model, label, z_dim=100, mode='uniform'):
gen_model.eval()
z = create_noise(1, z_dim, mode).to(device)
label_tensor = torch.tensor([label], dtype=torch.long, device=device)
with torch.no_grad():
generated = gen_model(z, label_tensor)
image = (generated + 1) / 2.0
image = image.squeeze().cpu().numpy()
plt.imshow(image, cmap='gray')
plt.title(f"Generated Digit: {label}")
plt.axis('off')
plt.show()
generate_digit_by_label(gen_model, label=5, z_dim=128, mode='uniform')

label = torch.tensor([4] * 10).to(device)
z = create_noise(10, z_size).to(device)
with torch.no_grad():
images = gen_model(z, label)
# Plot results
fig, axs = plt.subplots(1, 10, figsize=(15, 2))
for i in range(10):
axs[i].imshow(images[i].squeeze().cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.suptitle("Variation for Label 3")
plt.show()

26.3.1. Practical Considerations#
26.3.2. Stabilizing Training#
GANs are notoriously difficult to train due to instability and mode collapse. Here are some techniques to stabilize training:
Label Smoothing: Use soft labels for the Discriminator (e.g., replace 1 with 0.9 for real images).
Feature Matching: Modify the Generator’s loss to match features from intermediate layers of the Discriminator.
Gradient Penalty: Add a penalty term to the Discriminator’s loss to enforce Lipschitz continuity.
26.3.2.1. Loss Function Variations#
Least Squares GAN (LSGAN):
Discriminator Loss:
Generator Loss:
Wasserstein GAN (WGAN):
Introduces the Wasserstein distance as a measure of divergence.
Discriminator (Critic) Loss:
Generator Loss:
26.3.2.2. Conditioning Methods#
Concatenation: Concatenate the conditioning variable \( y \) with the input at the input layer.
Projection: Use projection-based methods to incorporate \( y \) within the Discriminator.
26.3.2.3. Implementation Tips#
Batch Normalization: Apply carefully, considering the conditioning variables.
Learning Rates: Use different learning rates for \( G \) and \( D \).
Optimizer Choice: Adam optimizer is commonly used with carefully tuned hyperparameters.
26.4. Summary#
Check out the extensive list of GAN from this interesting repository